Let’s build some tests to exercise our order book. Test will not only include the basics, but we’ll throw in some tests to help get some performance numbers as well. Here is the idea:
The Basics
There will need to be some unit test for the basics. We should be able to add transactions with predictable and deterministic results. As we have no matching engine yet, the collections can overlap. Maintaining sort order is the priority.
Oops! The basic tests uncovered a bug. Sorting doesn’t quite work correctly. The idea was to have the best bid (highest price) and best offer (lowest price) as the first elements. Elements with the same price should be sorted by their order id (a proxy for the time the order was placed). But by using the comparison operator for “Order” and std::less for asks and std::greater for bids, we’re reversing the orders within a price level for bids.
To resolve this, we could sort both collections in the same direction. So for one collection the best would be on top, and for the other the best would be on the bottom. That does not seem ideal. Another option is to not use an “Order” object, but instead “Bid” and “Ask” objects. The comparison function could be different for the two. A third option is to keep the “Order” object for both sides but have a switch in the comparison object that knows if it is a bid or ask.
I will make the executive decision to split the “Order” object into “Bid” and “Ask”. Tests prove that the problem is fixed. See this commit on GitHub.
Performance Baselines
We want to get some performance numbers. So we will instrument where necessary and try to get some ideas on where the bottlenecks are. To do that, we will need to simulate a bit closer to the “real world”. Here is the plan:
We will create a collection of transactions in memory. Those transactions will contain randomized volumes and prices in a somewhat normal distribution around a central price. Transactions over the central price will be asks, under the price will be bids, and at the price will be a randomized choice of bids and asks. To prevent that logic from being part of our performance numbers, this will be done prior to bench marking.
Of course when it comes to real numbers, it will all depend on your hardware. So I will attempt to run it on a few configurations that I have and compare.
Should we use shared pointers and copy the pointers around? Or should we copy the objects into the collections and let the order book maintain object lifetime? That is a good question, worthy of some testing. Of course, performance is not the only consideration here. Maintainability, memory and simplicity of implementation should be considerations as well.
Here are the initial results:
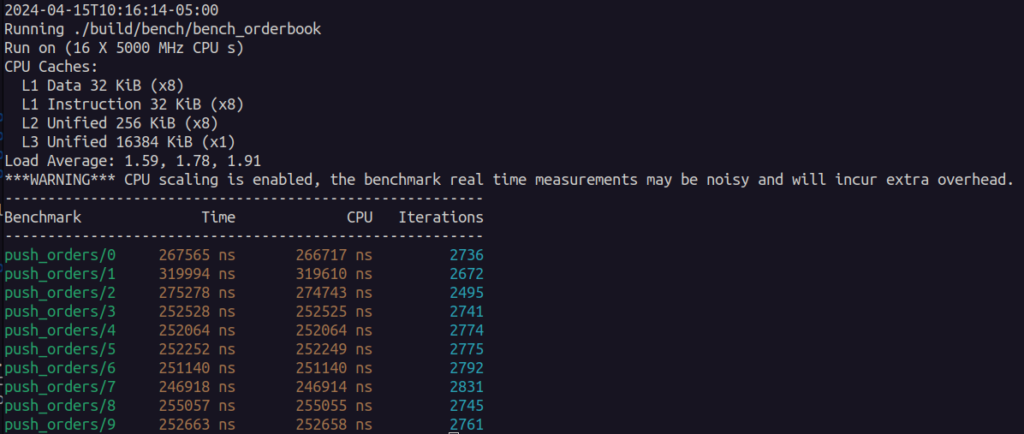
This benchmark was taken with the code at this commit.
To get indications on where the time is spent, we can use callgrind. If we run callgrind across the benchmarking code, we’ll get some of the Google Benchmark calls along with our own calls. The same if we use Google Test. Which is worse? Let’s find out. We will run both our unit test and benchmark test through callgrind and evaluate the result. This is more for academic reasons. I simply have never compared the two from a call stack standpoint.
First I ran callgrind across the unit test “basic.random” with the following somewhat expected results:
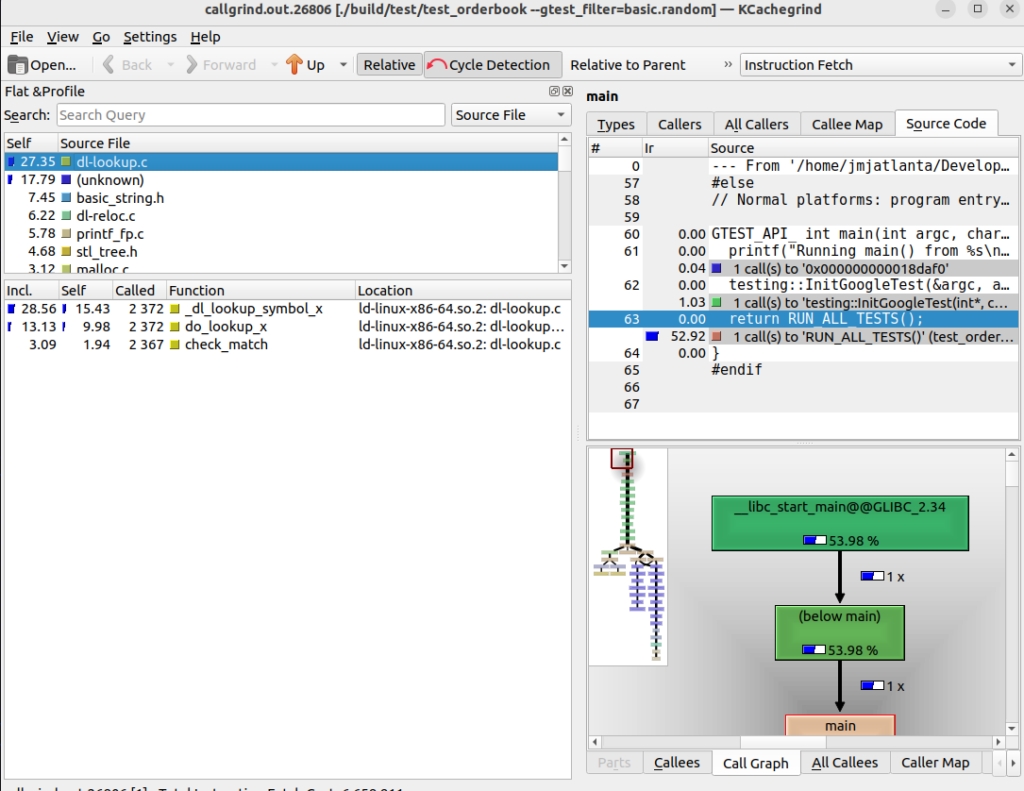
Much of the time was spent doing lookups in the sets. the basic_string.h is interesting, but probably due to the console output we do at the end. Looking at the “unknown” shows the stringstream functionality, so that is more evidence that we’re looking at console output. As that is done after the actual test, we can ignore that as a potential place for improvements.
Now let’s look and see if there is anything surprising in the results from running callgrind across the benchmark test…
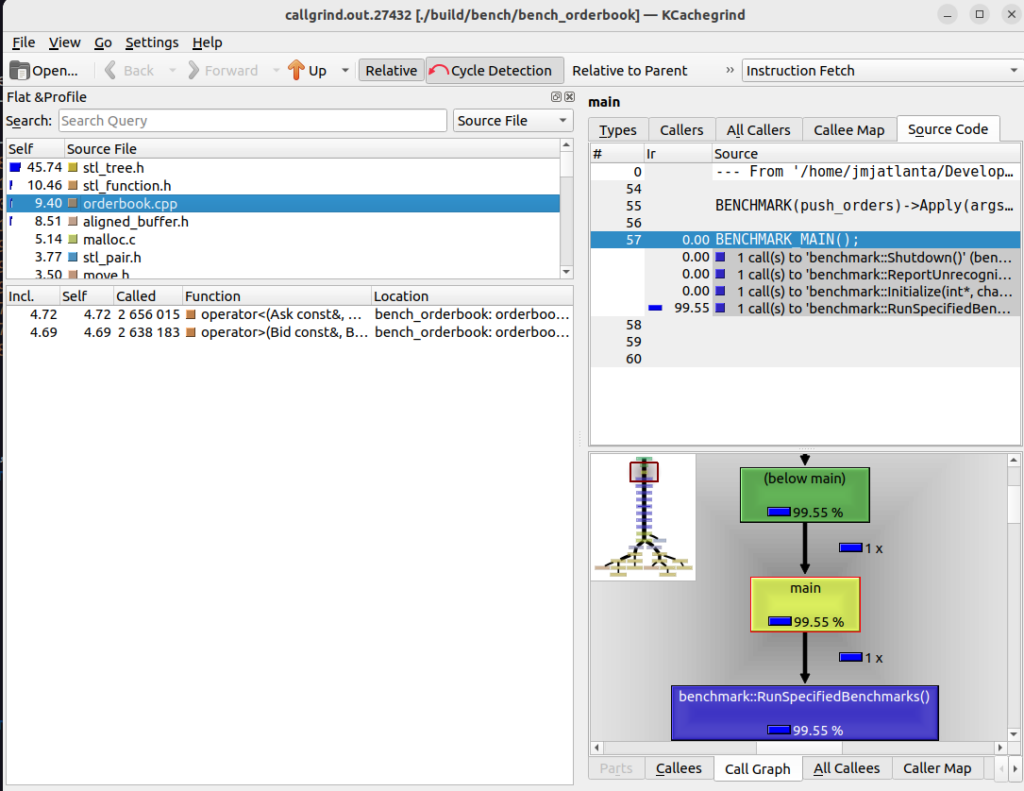
Once again, nothing surprising here. It does seem that the benchmark test shows more of our code instead of standard library internals. We’re spending a good amount of time in the comparison of keys. This may indicate that the “dl-lookup.c” time in our unit test is more related to generating output to the console than inserting an order in the set. So we will modify our unit test to not show output and see what that looks like…
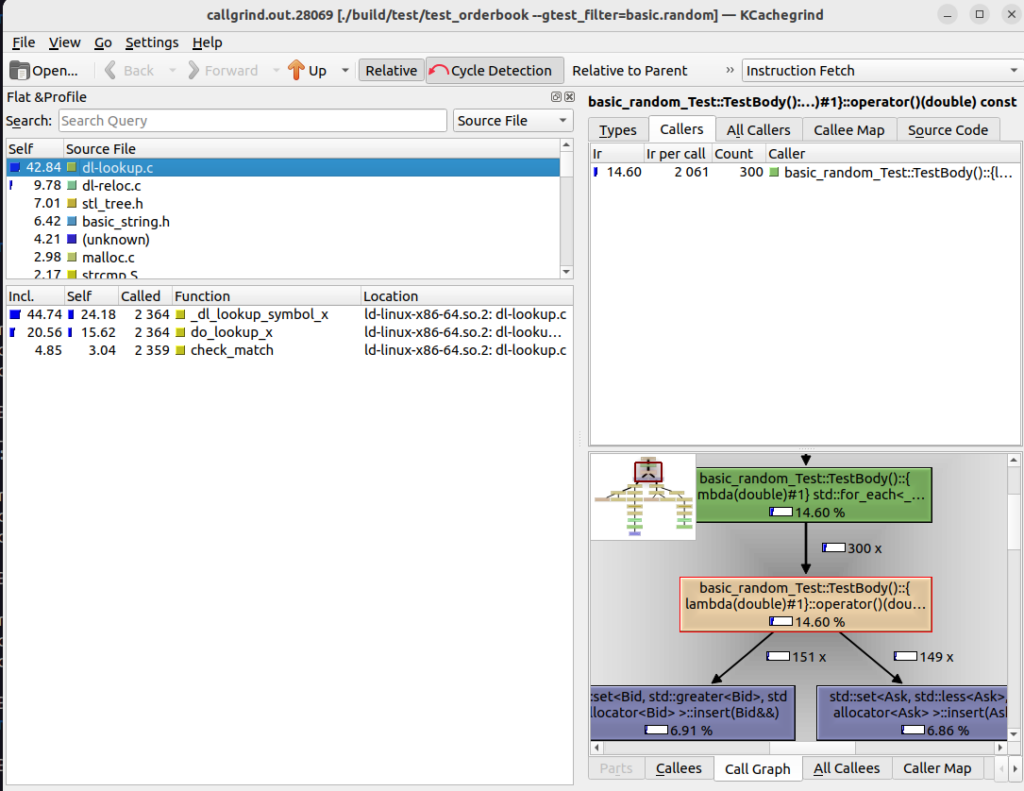
Surprisingly, this is similar to the first run of the unit test. The console output is not what was taking the time. Perhaps it is simply Google Test. We know we’re not doing anything with strings in our critical code path, so investigating further can be done at another time.
So what have we learned here?
- A naive order book can be done with standard library algorithms that are fast and convenient
- Unit tests can expose problems in your logic and verify functionality
- Google Test unit tests aren’t the best place to get performance numbers.
- Google Benchmark allows us to fairly easily get some performance numbers that are less noisy than Google Test.
Adding features
There is still some functionality to add in phase 1. We can add new orders, but we need to also be able to update and remove orders. Let’s finalize some business requirements: Adding is straightforward. Removing as well. Updating is an interesting one, as it could cause us to need to re-sort. The standard library is a bit unclear here, but as a general rule, the elements of your object that make up the key should be immutable. So modifying the id and price should not be allowed from a C++ standpoint.
From a business standpoint, modifying the order id would not be a good thing. So we will agree that the business requirements do not permit it. But modifying the price could be a required feature. What are our options if that were the case?
- Require the user to cancel and add a new order with the new price.
- Detect that the price has changed and cancel / re-add the order ourselves.
We’ll go with the second option. When an order is modified and a change in price is detected, remove the old order and insert the new. If quantity is the only change, modify the order in-place.
Here is where we run into a problem with an earlier decision. Even if we only want to modify the quantity, which is not part of the key, the iterators of the set only return constants. Here we have three choices:
- Switch to a container that uses a key/value pair instead of just a key.
- Set qty to be mutable. We will then be able to modify qty even if the object itself is const.
- Remove the element and add the new.
As we are already talking about option #3 for changes in price, perhaps we should stick with sets for now (instead of key/value pairs), and have the modify function always remove the old and replace it with the new.
That brings up the next issue. How do we look up the old order if the price changes? We have the id, but that is not the entire key. If the price changes, we currently have no way easy way to look up the order by id. Yuck! What are our options?
- A separate index that stores order ids and their original price
- Require the user to pass in the old price along with the new order
Option 2 is asking for trouble in my opinion. Using a separate index means we need to be careful to keep the two synchronized. Neither is a great option.
Boost has their multi-index containers. These are built for multiple lookup criteria on a single collection. Introducing them adds some complexity, but the payoff is a set of indexes that provide the functionality we need at the lowest cost. And building our own multiple index solution would certainly add more complexity than Boost’s container and probably with lower performance.
To hide the complexity, we’re going to hide the collections behind an interface using the pimpl idiom. With all that implemented, let’s take a look at what it cost us:
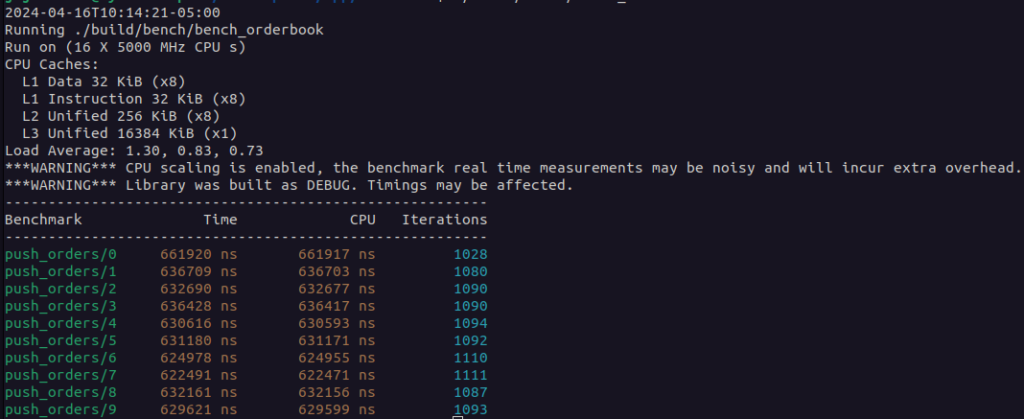
The code is available at this GitHub commit. A jump from 200k to 600k. That is 3x slower. Ouch! Let’s run it through callgrind and see what comes out:
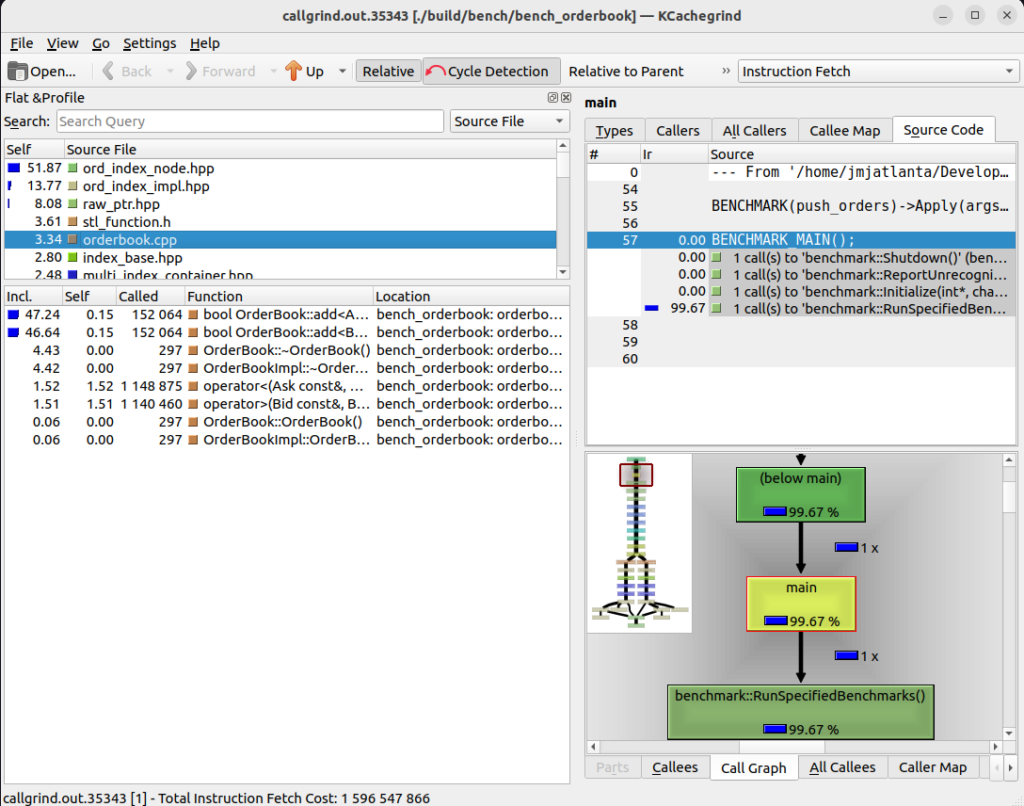
As one might guess, the time is spent in indexing. Is there something we can do to improve these numbers? Yes there is. But one must be careful. We may spend our time optimizing for this situation at the cost of another. This is the trap of premature optimization. Tweaking the addition of orders to the order book is a good academic exercise, but it won’t help us reach our goals. We want a fast system overall. To do that, we need to focus our attention on modeling realistic scenarios. We then measure and tune for that.
Is there a chance that the tweaks we make to adding orders helps improve the overall functionality of the system? Yes. But there are at least two issues with that reasoning:
- We don’t know the performance of the overall system because we haven’t built it yet. We must measure. To measure, the system must exist. So we have more work to do on the overall system.
- Spending our time here means either less time for other things or extending our time for project completion.
Instead, let’s get back to building a bench test that puts this order book in a scenario closer to reality. Adding orders will happen often. The matching engine will be editing and deleting orders (almost assuredly) more often. To understand how often, we will need to know a bit more about how our matching engine works.
The matching engine
The next design decision to be made is whether incoming orders go to the book first or the matching engine first. Who is the “owner” here? Does the matching engine use the order book for storage, or is the matching engine a service running along side the order book? We will walk through those two scenarios.
Order book is the owner – Orders are placed in the order book. This may show some strange looking situations. There may be bids on the book with a price greater than the lowest ask. While this may feel wrong, it is actually somewhat common. So we can plan for that if we need to.
Any book-level events can be the responsibility of the order book itself. Having the orders go through the order book first leads to a flow that is somewhat easy to follow. There are no “missed” steps in how an order is processed when a cross happens. Is this a good thing? Perhaps.
Matching engine is the owner – Orders are given to the matching engine, which decides how to change the state of the order book. Pending crosses can still appear (think about orders coming in before the market open) so we will still have to plan for that.
Book level events will still emanate from the book, but the market engine will be producing events as well. An incoming order may never make it to the book, but instead only remove liquidity due to a cross.
One of our major business requirements is that these systems must be deterministic. Once sequential identifiers (of an order or a transaction) are assigned, they must be processed in order with repeatable results. Should it be necessary to rewind and replay a sequence of events, the results should be the same.
But wait a minute. We set out to make an order book, not a matching engine. Why are we talking about this? Because if we want to pair up with a matching engine, we must know how it works so we know how our order book should behave. We also have a better chance of improving performance of the order book if we know how it will be used. And the matching engine will (almost assuredly) be the major user of the order book. So let’s bubble back to the top, make some design decisions, and see how that affects the design of our order book.
The matching engine will own the order book. This actually makes many things easier. There is now only 1 producer and possibly many consumers. State can be reconstructed at any point by knowing the state at a particular time and replaying the events fed it from the matching engine from that point forward. This makes the order book very deterministic.
Knowing that orders may never be added to the order book means that our focus should be on the performance of order deletion and editing. We will still have to make some assumptions about how orders come in.
To Be Continued…
[…] You can see the project up to this point on GitHub. The next step in our journey is documented here. […]